If you are anything like me, posting on instagram and most other social media is a challenge. What kind of content is news worthy, what will people find interesting and engage with? How do I even use this kind of short form content, when I am used to writing longer academic prose? Even writing medium posts can sometimes seem daunting.
This challenge becomes a real obstacle when you want to drive commercial interests for your small startup on IG. With limited capital for marketing, and an ever increasing demand for presence and content generation you have to use every advantage you got. And what I have is a tool box full of data analytics, applied statistics and curiosity. With that, here is how I got started.
Getting some inspiration
As with any new field I start out by doing research. What are other people doing and what seems to make for engaging content. Obviously, here I focus on content within skincare and adjacent fields. I also dive a bit into the scientific literature on modelling of engagement on IG. Here two articles in are of interest. The first, Cuevas-Molano et al [1] as it shows there are certain, almost formulaic components, that can explain a high degree of the engagement statistics (73.1%). However, their handling and coding of the variables does not lend itself to easy analysis of topics, tone of voice and similar which will become important later. The second, Xie-Carson et al. [2] shows that generated content (here in the form of human like avatars) does not alienate consumers. From the conclusion of the paper: “Overall, the majority of respondents (81%) indicated that they would not change their engagement preferences.” … “This suggests the insignificance of influencer presence (regardless of being real or not) in tourism promoting posts, further explaining respondents’ preferences of setting-only images”. One hypothesis is than that generated content can be OK, but it depends on the industry and the actual image used.
Taken together I learned that:
- There is a formulaic approach to content with high engagement
- Generated content can be OK, or at least serve as a basis for refinement
- Even generated images can work, but I need to be transparent on the usage
- There is a lot of data to learn from
- Coding of the data needs to be done in such a way that new content can be generated
None of these insights are novel, but serves as a solid basis for the next steps.
Getting the data
With a plethora of IG posts the first question is what brands have a tone of voice and content that aligns overall with our brand. Here as an example I use Paula’s Choice as they have good educational material, and are viewed as a more scientific brand.
Using Apify it takes about 5 minutes to setup a free account and scrape a small sample of 500 posts from paulaschoice instagram. This can then be downloaded as a json file with the caption, number of likes and number of comments, number of video views etc.
The data is easily extracted into a more usable format using Python. Here I extract the caption, likesCount , commentCounts, videoViewCount into numpy arrays as this is my preference.
Data Sanity check
So according to the literature there should be formulaic components to these captions that could predict the overall engagement of the posts. This can be tested in various ways, but a straight forward and crude method is logistic regression based on the tf-idf frequencies of the tokens in each caption. So normalize the engagement statistic for likes and comments using 0.5*(likes/max(likes)) + 0.5(comments/max(comments)) or some other weight scheme. Convert the normalized scores into a binary indicator (for the logistic regression) using a threshold of the 75th percentile. Build the logistic regression model on 75% of the data, and test on the remaining 25% — create a confusion matrix and hope for the best. This gives a very low predictive value, and an abysmal confusion matrix.
Refining the analysis a bit using a negative matrix factorization to extract some abstract topics from the captions, and using ridge regression for the prediction of good vs bad engagement. I am able to push it to around 0.61 in accuracy, pushing this to 0.63 with a standard Random Forest model. Not great, but could it indicates that there is some tiny signal in there.
Enter super-intelligence
With all the fuss about reaching AGI and Q* breakthroughs at openAI, it was time to see if their Data Analytics and generative capabilities can help me.
I upload a simple file of the normalized engagement statistic, and the associated caption, 500 entries in total. And ask chatGPT to do some basic analysis of the data — identical to what was done above.

Hmm, I guess that makes sense. Since chatGPT can’t download libraries and build standard sklearn models there must be another way.
Instead I try to make sure that chatGPT “understands” the nature of the data by giving me back top and bottom engagement posts. This works. Then I ask it to generate a post, using this information, for one of the products we currently have in our pipeline, together with some detailed information about one of the key ingredients. It looks like this:
“🌟 Unveil the Science Behind Brighter Skin with DS10 Serum! 🌟
Meet Acetyl Glycyl β Alanine, the powerhouse ingredient in our DS10 Serum, revolutionizing the way we tackle dark spots. 🎯✨
🧬 How Does It Transform Your Skin?
- Upstream Action: It works upstream of melanin production, effectively down-regulating enzymes that trigger melanogenesis. This means getting to the root of dark spot formation!
- Powerful Inhibition: It inhibits key factors like stem cell factor (by 61.3%) and endothelin-1 (by an astonishing 91.7%) — crucial in the melanocytes and keratinocytes communication that triggers melanin production.
- Melanogenesis Regulation: Downregulates MITF mRNA by 39.0%, putting a check on the melanin generation process.
- Enzyme Activity Reduction: Reduces tyrosinase, TRP-1, and TRP-2 activities by up to 79.1%, 42.1%, and 91.9%, respectively, directly impacting melanin production.
- Interrupting Melanosome Transport: It decreases Mlph expression by 69.1%, disrupting melanosome transport.
- Reduces Melanosome Uptake: By reducing keratinocyte uptake of melanosomes by 55.1%, it ensures lesser melanin in skin cells.
🔬 Why is this important? Because tackling dark spots isn’t just about surface treatment. It’s about understanding and addressing the underlying process. 🌱
🌟 Experience the DS10 Serum and watch your skin transform with science. Say goodbye to dark spots and hello to evenly toned, radiant skin.
✨ Tap to shop and start your journey to flawless skin. Don’t just take our word for it — see the science for yourself.
#BrighterSkinWithScience #DS10Serum #FightDarkSpots #SkincareScience #PaulasChoice”
Impressive, it even put PaulasChoice (the training data) in the hashtag. And it meticulously incorporated all the details I give it. I don’t think gene names and percentages does too well on IG. Lets try again, with a focus on the benefits instead:
“🌟 Discover Radiant Skin with DS10 Serum’s Secret Ingredient 🌟
Dive into the magic of Acetyl Glycyl β Alanine, the star component of our DS10 Serum, expertly crafted to transform your battle against dark spots. 🌈✨
🔬 Why Acetyl Glycyl β Alanine? Here’s what it does for your skin:
- Targeting the Root: Works effectively at the very start of melanin production, tackling dark spots right from their origin.
- Powerful Impact: Inhibits crucial factors in the skin’s pigmentation process, significantly reducing the communication that leads to melanin production.
- Regulating Melanin: Puts a brake on the key regulators of melanogenesis, helping to keep melanin production in check.
- Enzyme Activity: Directly targets enzymes responsible for melanin generation, leading to a noticeable reduction in dark spots.
- Interrupting Transport: Slows down the transport mechanisms of melanin, helping to prevent the accumulation of pigmentation.
- Reducing Uptake: Lessens the amount of melanin that’s absorbed by skin cells, contributing to a more even skin tone.
🌿 Embrace the DS10 Serum and witness a visible transformation. Our formulation is not just about treating the surface; it’s a deep dive into the science of achieving and maintaining a beautifully even skin tone.
💫 Ready for skin that radiates health and beauty? Tap to shop the DS10 Serum and start your journey to a brighter, more even complexion. Embrace the glow of science-driven skincare.
#RadiantSkinRevolution #DS10Magic #PaulasChoice #SkincareScience #NoMoreDarkSpots”
OK, this might be a better starting point. I now try to get chatGPT to optimize the posts by giving it more creative freedom. This results in giveaway posts where people would get free samples of the serum if they post before and after images of how the serum works, clearly a circular logic fallacy.
Predictive content generation
Instead of just generating content, what if chatGPT could also score its own content, or content that I had made? This proves a bit difficult, again due to the limitations of building specific models in the environment. Instead I opt for this:

Now prompting chatGPT with examples to score fails miserably, and the code only looks for matches in the already uploaded files.
# Re-importing and parsing the data from the provided file to analyze similar captions and their engagement scores
file_path = '/mnt/data/pchoice.txt'
with open(file_path, 'r') as file:
contents = file.readlines()
# Parsing the data into engagement statistics and post captions
engagement_stats = []
post_captions = []
for line in contents:
parts = line.strip().split(' ; ')
if len(parts) == 2:
engagement_stat, post_caption = parts
engagement_stats.append(float(engagement_stat))
post_captions.append(post_caption)
# Finding the engagement score for the provided caption
provided_caption = "meet your barrier s new best friend resist barrier repair advanced moisturizer clinically proven to improve skin s barrier within 30 minutes hydrate all day our newest moisturizer unlocks the power of your own skin by giving it the tools it needs create its own ceramides self hydrate so your natural barrier is working at its best featuring skin firming tripeptide 5 replenishing skin identical ceramides cholesterol nourishing watermelon seed oil shop the resist barrier repair advanced moisturizer at paulaschoice com vis link in bio amazon sephora com u s only paulaschoice skincare skincareroutine barrierrepair moisturizer"
estimated_engagement_score = None
# Searching for the exact or similar caption in the parsed data
for stat, caption in zip(engagement_stats, post_captions):
if caption.strip() == provided_caption.strip():
estimated_engagement_score = stat
break
estimated_engagement_score
Not great, and not some kind of super intelligent behaviour.
As a last effort I try to get it to generate a new post and as part of generation also provide the engagement statistics.

This enables me to now upload other content examples and get some kind of score. But this seems off as I had no idea of what would generate a high and a low score respectively. So I ask:
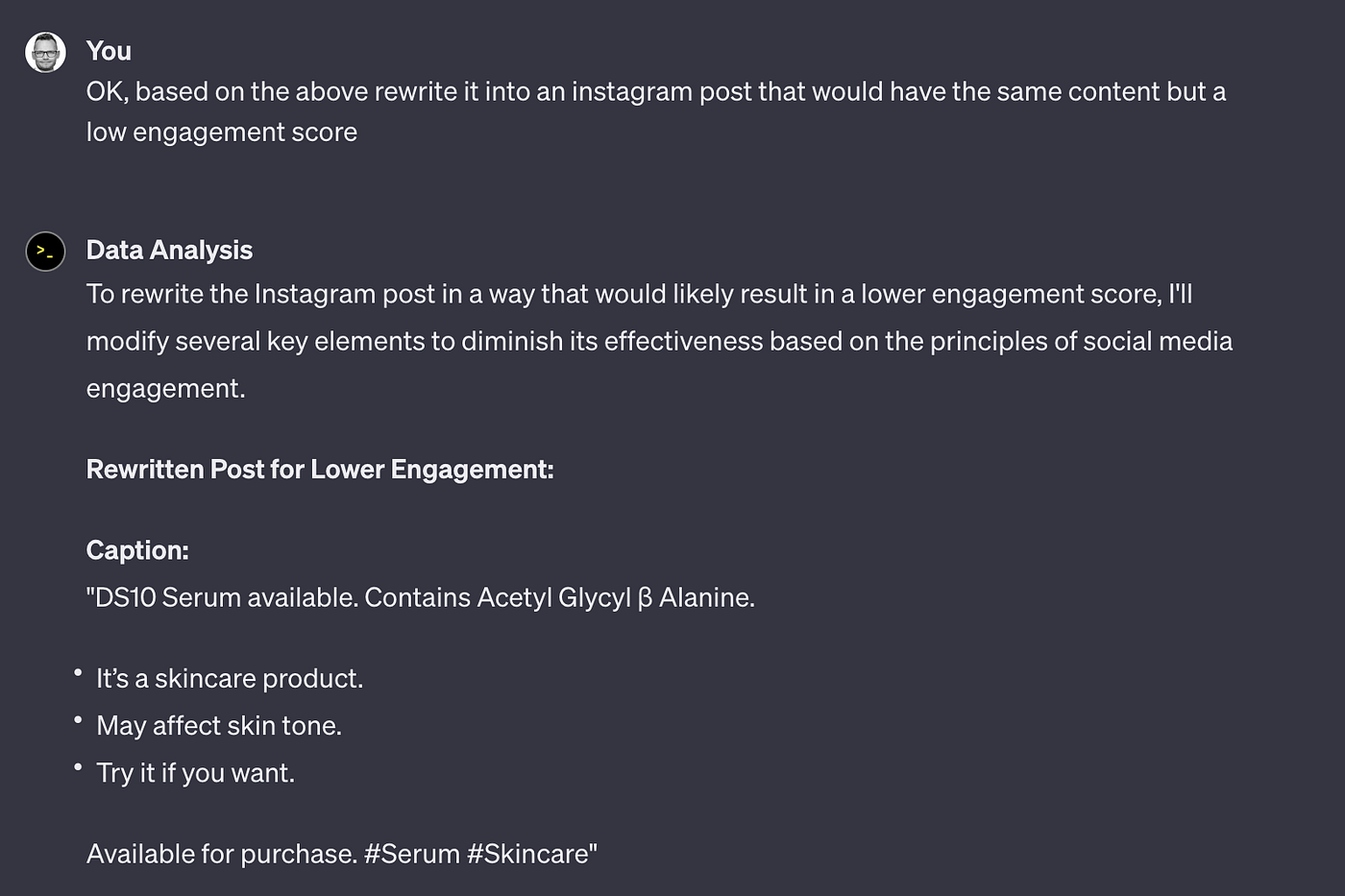
This reply made me laugh! The dullness and matter of factness in this post is 🤣. Even I can figure out that this will be below par.
Conclusions
While the data analytics part of chatGPT leaves much to be desired, its generative capabilities continue to be impressive. As others have already pointed out, the ability to do few short learning by providing examples works well in this context. It was not possible for me to figure out if the engagement statistic was actually used when generating content. This would likely require shuffling the engagement score between generations and get some kind of scoring of the generated content.
The inability of producing a good scoring function by the system is interesting. I have a sense that we will see more and more of this kind of behaviour, where generative systems, in silico, comes up with suggestions and we now need the standard analog world to test those ideas in. This could for instance be new suggestions for chemical compounds with specific mode of actions which needs to be tested in the relevant assays. Images that needs to be graded by humans, similar to midjourney’s image ranking, or the RLHF used to fine-tune LLMs.
I guess for content creation, the only way forward is to get inspiration and quick iterations and really test with ones audience to figure out what works.
References
[1] E. Cuevas-Molano, L. Matosas-López and C. Bernal-Bravo, “Factors Increasing Consumer Engagement of Branded Content in Instagram,” in IEEE Access, vol. 9, pp. 143531–143548, 2021, doi: 10.1109/ACCESS.2021.3121186.
[2] Li Xie-Carson, Thomas Magor, Pierre Benckendorff, Karen Hughes,
All hype or the real deal? Investigating user engagement with virtual influencers in tourism, Tourism Management, Volume 99, 2023,104779,
ISSN 0261–5177, https://doi.org/10.1016/j.tourman.2023.104779.