Google DeepMind released AlphaEvolve (blog and paper) which is essentially an automated innovation engine. In the current version the system is constrained to only work on problems that can be computationally evaluated.
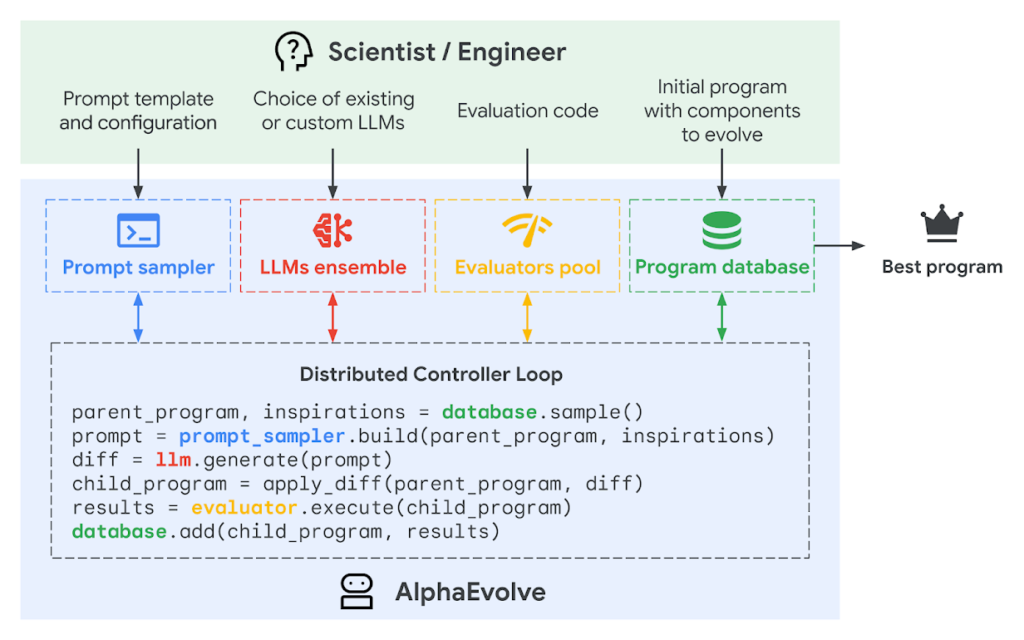
Essentially, a LLM searches over a series of proposed solutions / innovations which are then scored by some metric. This is done in an iterative fashion until a solution that is on par with or surpassing the current state of the art is found. Impressively the team showed that for multiple diverse problems in engineering, computing and mathematics the system can surpass the current best human solutions.
Why it matters
This might not look like much at the surface, but try to think back on AlphaGo and AlphaFold. AlphaGo introduced the concept of self-play and removed the need for massive amounts of human labeled data, or prior training data all together. The system could evolve on its own to beat the world champion. Similarly, AlphaFold has changed fundamentally changed structural biology and essentially solved 3D structure prediction of proteins, allowing accelerated research across the life sciences, and a predicted structure for 200 million proteins – nearly every known protein for every sequenced organism.
If we look at AlphaEvolve it consists of the following parts:
- A problem definition
- An evolving sampling approach of solutions from an LLM
- A database of scored solutions
- Some kind of “objective” scoring function relevant to the problem
What is important here is the “objective” scoring function. Say you replace that with A/B testing on an e-com site for conversion. Now you have an automated system for UX / copy / creatives. Replace the objective function with a simple in-vitro testing system and you have an automated synthetic biology system. Same for material sciences. Or even corporate innovation. Most of the time we score innovation ideas by a governance board. These human experts might as well be replaced by LLM avatars that have been instructed in a given scoring rubric.
In short:
AlphaEvolve is AlphaGo for innovation. We’re seeing the beginning of agentic systems that don’t just play games—but play the game of invention itself.
Maybe the future of innovation is not about human alone endeavours, but a carefully crafted system of human, computer and strong feedback loops. The greatest challenge here will be building the feedback loop as not to create bottlenecks to the automated innovation system, and keeping the right set of guardrails for ultimate human decision making.